



When developing a product that handles extensive data and is used by many people, ensuring a swift response from your backend system is crucial. Slow product can disrupt the seamless user experience, potentially deterring users from purchasing or engaging with your product. The first thing you need to do when this kind of issue starts to happen is to identify where the performance bottleneck is. And, the most common bottleneck occurs in your database. One of the first steps you can take to reduce the response time of your database is to ensure your high throughput queries have indexes. But, what is a database index? In this article, we'll learn about:
- What is a Database Index: We'll start with the basics: what a database index is and how a common type helps speed up your queries.
- How a Database Index Works: Let's dig deeper into how a database uses a specialized data structure, like the B-Tree, to make searches lightning-fast.
- Why You Should Use a Database Index: We'll illustrate the difference an index can make by comparing queries with and without one.
- Common Types of Database Index: We'll explore types like single-column, unique, compound, and partial indexes – and when to use each.
By understanding and implementing database indexing, you can significantly improve the performance of your applications, leading to a better user experience and potentially higher user retention and satisfaction.
What is Database Index
Imagine you have a personal collection of books. If it's only three or five books, finding the one you want to read is simple because you can quickly glance at each one. However, consider having a library with thousands or even millions of books. How would you locate a specific book you're looking for? Libraries solve this challenge by using a cataloging system.
Each book is assigned a unique location on the shelves, identified by a combination of row, column, and shelf number. A directory, either on paper or digitally, records each book's title, author, and its precise location using these coordinates. This system acts like an index in that you can quickly find the book by looking up its details in the catalog and then going directly to its location in the grid.
This method allows for multiple searchable lists within the same directory, such as by title, author, or subject, making it incredibly efficient to locate books. By referencing the directory, you bypass the need to scan every book on every shelf, saving time and effort.
Database indexes function similarly. Initially, data in each table is sorted by primary keys. When an index is created, the database generates a sorted list that maps the values of the data to their storage locations. Just like a library, a database might handle millions or even hundreds of millions of entries, or even billions. While a sorted list is effective for quickly locating a small number of entries, it becomes inefficient for millions. To enhance speed, the database employs a data structure known as a B+-Tree (B Plus Tree). Implementing indexes is a standard strategy to overcome performance bottlenecks in databases. Major databases like PostgreSQL, MySQL, and MongoDB all support indexing.
How Database Indexing Works
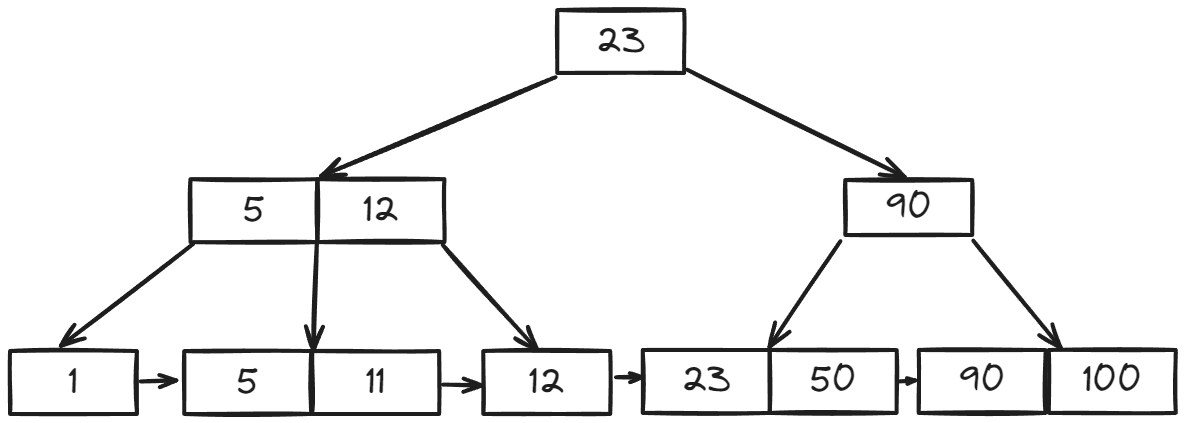
B+-trees are a specialized data structure based on self-balanced search trees. This self-balancing ensures that retrieving any data takes roughly the same amount of time. Additionally, rather than storing data on every node, B+-trees store data only on leaf nodes, with the leaf nodes linked together. This design makes them particularly efficient for range queries, where you need to retrieve multiple related data points.
Let's use your example of 8 data points to illustrate how to find "23" in a B+-Tree.
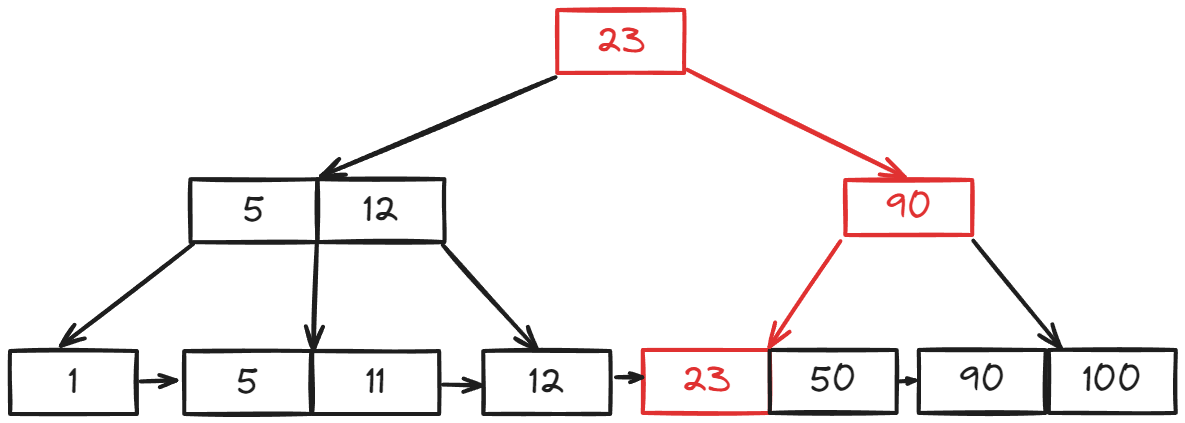
23 in the root node of our B-Tree, that root node just holds a pointer to its child node. We'd still need to traverse the tree to the corresponding leaf node where the data is stored. This traversal has a time complexity of O(log(n)), a significant improvement over the O(n) complexity of searching a simple sorted list.Databases often handle queries that involve ranges of data, rather than just single values. The B+-Tree design is well-suited for these range queries because leaf nodes are linked sequentially. This allows for efficient retrieval of all data points within a specified range. For example, if we want to query numbers from 23 to 100, we can:
- Locate the leaf node containing the starting value (23).
- Traverse the linked leaf nodes, collecting values within our range.
- Stop when we encounter a value greater than 100.
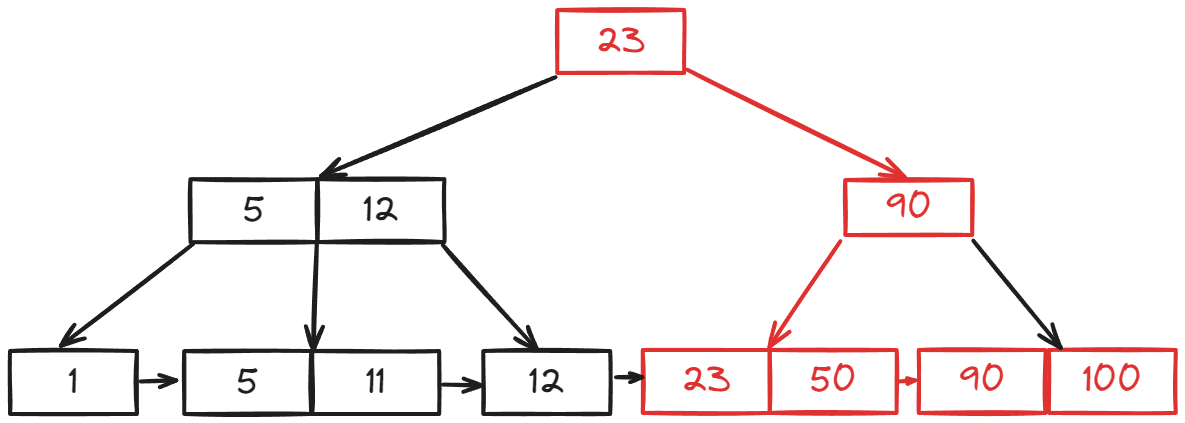
As you can see, adding the pointer from 23 to 100 lets us traverse directly between leaf node clusters without going back up the tree. This might seem like a small gain, but in a database with massive amounts of data, this kind of optimization significantly improves query performance.
Remember, B-Trees in databases don't just store the numerical values in their leaves. They also include pointers to the actual data – whether that's a disk address, a row ID, or a direct pointer to the data itself. This means your database can quickly fetch the complete data you need.
Why Should You Index Your Database
When you're experiencing performance bottlenecks in your system, one of the first things to investigate is whether your database queries are effectively using indexes. Database indexes can dramatically improve query speed with only a minor trade-off in storage and data insert speed. Let's illustrate this with an example.
Consider creating a table called test_table with the following columns:
unique_value: A UUID value ensuring uniqueness for each row.moderate_value: An integer column with values ranging from 1 to 1 million.
The following snippet contains the code to create the table and fill it with 10 mio data:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE test_table (
id SERIAL PRIMARY KEY,
unique_value UUID NOT NULL DEFAULT uuid_generate_v4(),
moderate_value INT NOT NULL
);
INSERT INTO test_table (moderate_value)
SELECT
(i % 1000000) + 1
FROM generate_series(1, 10000000) AS i
To effectively analyze the performance of your PostgreSQL query using the moderate_value as a filter, you can use the EXPLAIN ANALYZE command. This tool provides detailed insights into the execution plan of your SQL query, showing you how PostgreSQL processes your request, including the use of indexes, sequential scans, and more. Here’s how you can structure your query to make use of this feature:
EXPLAIN ANALYZE SELECT * FROM test_table WHERE moderate_value = 100;
This is the result that I got from the machine I used:
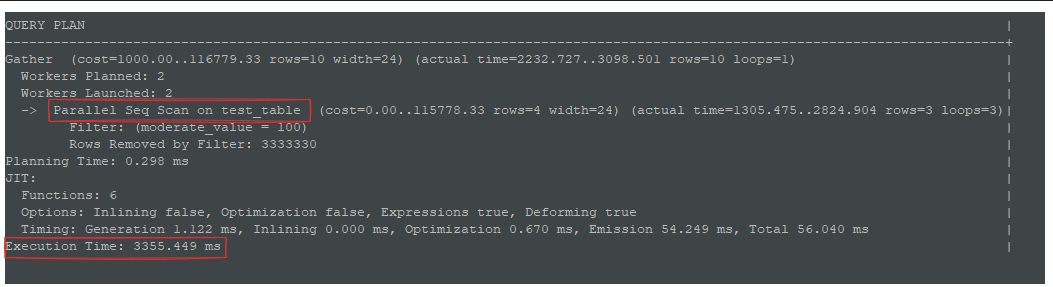
The database provides a lot of information from EXPLAIN ANALYZE, but let's focus on two key parts:
- 'Parallel Seq Scan': This indicates that PostgreSQL is performing a full table scan to find rows where
moderate_valueequals 100. - 'Execution Time': This tells us how long the query took to complete.
Now that we have a performance baseline, let's create an index on the moderate_value column and see how it impacts our query.
CREATE INDEX idx_test_table_moderate_value ON test_table(moderate_value);
EXPLAIN ANALYZE SELECT * FROM test_table WHERE moderate_value = 5432;
The result is:

As we can observe, utilizing an Index Scan as opposed to a Sequential Scan has a dramatic impact on performance. When we compare the execution times, the difference is stark: by using an index, we've reduced the execution time from 3 seconds to just 0.073 milliseconds.
In addition to the speed enhancement, using an index scan also means that your database does not need to scan the entire table. This reduction in unnecessary data processing prolongs the lifespan of your hardware resources, including CPU, memory, and disk, as a more efficient querying process lessens wear and tear.
However, indexing is not without its drawbacks. Creating an index increases disk usage due to the additional space required for the index files. Moreover, because a B+-Tree is a balanced tree structure, the database must rebalance the tree after each write operation. For example, if you have five indexes, each write operation necessitates rebalancing all five trees. While this overhead is often negligible if your table has few indexes, it can significantly slow down your database when there are too many unused indexes.
To ensure your database maintains optimal speed, remember to not create indexes you don't need: The more indexes you have, the more processing your database must perform during write operations.
Common Types of Database Index
Every database supports a different set of database index types. Even MySQL and PostgreSQL, which both use SQL as their engine, support different database indexes. However, despite these differences, there are common database indexes that exist in most databases.
Single Column Index
CREATE INDEX index_name ON table_name (column_name);
A single column index is the most basic type of indexing. We've explored this type of index previously in the section "How Database Index Works." It is created on only one column of a table, designed to improve the performance of queries that filter or sort data based on that column.
Compound Index
CREATE UNIQUE INDEX index_name ON table_name(column1, column2)
A compound index is an index that can hold multiple columns instead of just one. When retrieving data from your database, you don't always query with a single column. Single column indexing would help with multi-column queries, but it won't be very efficient because it could only use one of the columns. Using a compound index for compound queries ensures that your query will be able to fully utilize the index.
Tips on column order in compound index
When creating a compound index, you need to be aware of your order of the columns. Cardinality refers to how many unique elements exist within a database column. The more distinct values a column has, the higher its cardinality. Creating a compound index ordered by its cardinality is what generally people agree to be the best way to order the columns. However, in my own testing, ordering the columns by their selectivity has been the most beneficial.
The ESR (Equality, Sort, Range) rule is a guideline that determines the order of columns you should create based on their selectivity. Basically, you should order your index by how the data is accessed in the query. Generally, you should index your data by:
- Equality: The "Equality" component of the ESR rule refers to columns that are often used in queries with equality conditions (
WHERE column = value). When creating indexes, these columns should be placed first. This is because the database can quickly eliminate non-matching rows and effectively narrow down the search to relevant rows at the beginning of the index scanning process. - Sort: The "Sort" part of the rule applies to columns that are commonly used to sort the query results (specified in
ORDER BYclauses). When these columns follow equality columns in an index, the database can use the index not only to filter data but also to avoid a separate sort operation, which can be costly in terms of performance. - Range: Finally, the "Range" component deals with columns that are used in range conditions (e.g.,
WHERE column > valueorWHERE column BETWEEN start AND end). These should be placed last in the index because once a range filter applies, any subsequent columns in the index cannot be used for jumping directly to specific index entries as effectively.
Unique Index
A unique index is an index that doesn't allow multiple entries to have the same value on a specific column. The common use case for this index is to enforce uniqueness on columns that must have unique values. A unique index can also prevent duplicate data insertion patterns that usually occur due to concurrent requests or a retry pattern.
For example, if you have a users table that's used to store user authentication information, it contains username and password. In this case, you don't want more than one entry with the same username to exist in your database. To ensure this, you can create a unique index for the username column:
CREATE UNIQUE INDEX idx_unique_username ON users (username);
Partial Index
A partial index is a type of index that instead of indexing the whole table, only creates an index for the data included in your filters. The advantage of using a partial index is to keep your index as lean as possible to help with both write and read queries. For example, if you have a users table with a soft delete mechanism (where you mark users as deleted instead of actually deleting them), what you can do is add a deleted = FALSE filter:
CREATE INDEX idx_deleted_username ON users(deleted, username) WHERE deleted = FALSE;
Another way to use a partial index is to combine it with a unique index. When combined with a unique index, the database only needs to guarantee that the data filtered is unique. This way, if you have a certain column that you need to be unique but not for all data, you can use this type of index. Let's return to our users table example. Suppose you don't want to allow the same username to be created, but only for data that is not deleted. You can create the following index:
CREATE UNIQUE INDEX idx_unique_deleted_username ON users(deleted, username) WHERE deleted = FALSE;
Takeaways
In this article, we've explored what a database index is, how it works, and how to use them efficiently. Mastering indexing is crucial if you aim to build a performant and scalable system. While we've covered some types of indexes like single-column, compound, and unique indexes, there are many others out there, such as bitmap, full-text, and spatial indexes, each tailored to specific types of data and queries.
Beyond what we've explored, there is much more to learn about database indexing. For instance, you can detect queries that need an index by examining slow query logs, and learn how to maintain indexes effectively to prevent slowdowns by periodically rebuilding them.
If you're interested in further enhancing your system's performance, be sure to read my other article about caching!


