



Consistency in a database is crucial when building a system that serve many users. Imagine maintaining a concert booking system, and a very famous artist has just started selling assigned seats to the concert. Many people start purchasing seats as soon as the selling time begins. What you don't want to happen in this case is for seats to be oversold, resulting in more than one person being assigned to a single seat. This could cause a disaster at the event as people might fight for their seats, ultimately damaging your reputation as the person managing the booking system.
In this article, we will explore how concurrency works in databases and how to prevent the scenario mentioned earlier from happening. We'll cover:
- Why Databases Use Locks: We'll delve more thoroughly into the previous example to understand what's happening and why database locks can prevent such issues.
- Shared Lock and Exclusive Lock: There are two types of locks based on how they lock processes. We'll learn about them.
- Read Phenomenon and Isolation Levels: The more consistency you want in your database, the stricter the database lock process will be. Inconsistent reading in a database is known as a read phenomenon, and it can be managed by adjusting the isolation level of a database.
- Types of Locks: We'll check out different types of database locks, how they behave, and when to use them.
Why Databases Use Locks
For starters, let's explore our concert booking system and break down how race conditions can occur. Suppose we have the following simplified schema for the database:
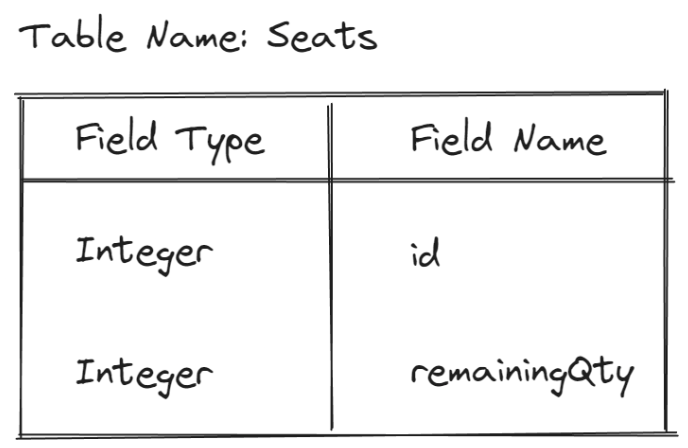
Let's create a simplified query of how we can book the seat:
BEGIN;
SELECT * FROM seats WHERE id = '1';
UPDATE seats SET remainingQty = remainingQty - 1 WHERE id = '1';
COMMIT;
BEGIN; and COMMIT; are SQL command that indicates when the transaction started and ended. The SQL database will ensure that the operations between them are executed atomically.Now let's see how the transaction would work if there are concurrent processes operating on the same row:

As you can see, there are two different processes working on the same row. As a result, both processes will indicate that their respective booking is successful. The seat that only had one available spot now has multiple bookings.
This issue is called a race condition, and it's a common problem in multi-threaded applications. Thankfully, databases have a built-in locking mechanism to prevent this from happening.
Moving forward, we'll explore how the database locks work. At the end of the article, we'll figure out how to solve the concert booking example (note: it's actually quite simple).
Shared and Exclusive Lock
There are two types of database locks related to their functionality: Shared Lock and Exclusive Lock.
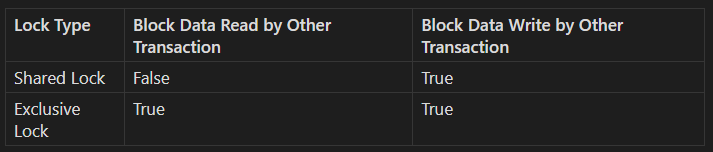
When a row is locked with a Shared Lock, other transactions are prevented from writing to that row. This lock is typically used when a transaction is reading a specific row and needs to ensure that the data remains consistent throughout the transaction. Multiple transactions can hold a shared lock on the same row simultaneously, but no transaction can modify the row while it's locked in shared mode.
On the other hand, an Exclusive Lock locks the row for both reading and writing processes. Typically, when a transaction is writing to a row, it will place an exclusive lock on that row. This lock ensures that other transactions cannot read or write to the row while it is being modified. The exclusive lock ensures complete isolation of the transaction, maintaining data integrity by preventing concurrent access.
Read Phenomenon and Isolation Level
When reading data from a database, you can encounter inconsistent data due to concurrent processes working on the same data. This is known as a Read Phenomenon. Various read phenomena range from simple to more complex. To tackle this issue, databases allow you to set the Isolation Level for each transaction. The stricter the isolation level, the fewer read phenomena that can occur, but this may also slow down your database. This is because stricter isolation levels involve more complex locking mechanisms.
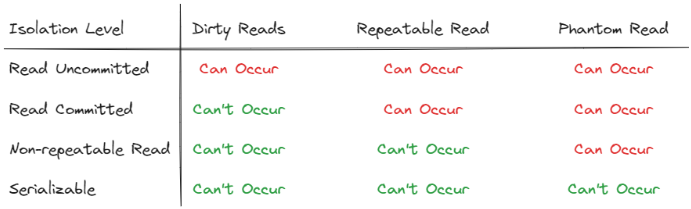
It is important to note that isolation levels can vary between SQL databases. To make the topic easier to understand, we will explore the simplest isolation level mechanisms that uses only Pessimistic Locking (we'll also explore the others in the next section).
Read Uncommitted
Read Uncommitted is the most lenient isolation level. At this level, there is no locking mechanism at all. This means that, as the name suggests, a transaction can read data from another transaction that has not yet been committed.
Although this is the fastest isolation level, it can cause issues when a transaction reads data from an uncommitted transaction that is later rolled back. This phenomenon is known as Dirty Reads.
The previously mentioned Race Condition example can also occur due to this level of isolation. Because of the high inconsistency that can happen with this isolation level, some databases, like PostgreSQL, choose not to support it at all.
Read Committed
The next isolation level is Read Committed. As the name suggests, at this level, the database will only allow transactions to read data that has been committed.
Starting at this isolation level, your transaction is prevented from reading data from another unfinished transaction. To achieve this, the database places an exclusive lock when a transaction is writing to a row, ensuring that other transactions cannot read or write to it until the transaction is completed.
Now, let's consider what could happen when you read from the same row twice within the same transaction:
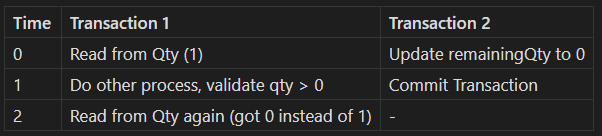
This phenomenon is called a Non-Repeatable Read. It occurs when a transaction reads the same row twice and gets different results each time, because another transaction has committed changes to the row in between the reads.
Repeatable Read
To combat the Non-Repeatable Read phenomenon, we can use the Repeatable Read isolation level. In this isolation level, your transaction will also place a shared lock on the rows you're working on. This means that if another transaction attempts to update the data before your transaction is completed, it will be blocked. This isolation level ensures that your transaction always reads the same value from a row throughout its execution.
However, this isolation level cannot handle a read phenomenon called Phantom Read. Phantom reads occur when you read a set of rows, and then another transaction inserts new rows that satisfy the criteria of your previous query. As a result, if you rerun the same query, the new rows (phantoms) will appear in the result set.
Serializable
The last isolation level we'll explore is Serializable, which is the strictest isolation level. In the Serializable isolation level, the database ensures that transactions run as if they were executed sequentially, one after the other. This means that effectively, only one transaction can modify data at a time, eliminating any chance of concurrency-related issues.
By ensuring transactions run in this highly isolated manner, the Serializable isolation level guarantees consistency. Transactions cannot interfere with each other, preventing all types of read phenomena.
However, this isolation level has a significant drawback: the elimination of concurrency. As a result, the database operations become much slower. The performance trade-off is substantial, as the database throughput is dramatically reduced when ensuring that transactions operate in a serial order.
Types of Database Locks
We've explored isolation levels and read phenomena, but we have only scratched the surface of what database locks are. The examples we used before rely on a mechanism called Pessimistic Locking. However, there are two other approaches to handling database concurrency: Optimistic Locking and MVCC (Multi-Version Concurrency Control). Databases and application frameworks usually use a combination of these locks to handle concurrent processes effectively.
Pessimistic Locking
Pessimistic locking is the locking mechanism we explored previously. It behaves such that when a transaction is currently modifying a specific row, another transaction must wait for the change to finish before it can modify the same row.
One important aspect of pessimistic locking is the potential for deadlocks. Deadlocks occur when two transactions are each waiting for the other to release a lock on different rows, resulting in both transactions being blocked indefinitely. To handle this, databases typically implement a timeout mechanism. If a transaction cannot acquire the necessary locks within the specified timeout period, the transaction is rolled back, and an error is generated.
Optimistic Locking
Optimistic locking is a type of locking that will fail a transaction if there's another transaction that has already modified the data.
You can implement optimistic locking by adding version field to your data. When you want to update a row, you'll first retrieve the row to get the version number. Then, you'll include the version number in your update filter. If no row is updated, it means another transaction has already modified that row, and you can conclude that your transaction has failed.
This also works for consistently reading a row twice (Repeatable Read). First, you need to snapshot the version number from the initial query. For subsequent queries, you'll include the version number or timestamp. If the query doesn't return anything, it means another transaction has already updated the row, and you should rollback the transaction.
Unlike pessimistic locking, optimistic locking can't cause deadlocks, so it is considered safer. However, you'll need a retry mechanism for writing to your database if you expect concurrent updates on the same row.
Multi-Version Concurrency Control
In Multi-Version Concurrency Control, or for short MVCC, your application will store multiple versions of a row. When you read from the row, your transaction will snapshot the version of the row. This process ensures that you will always get the same result, even if other transactions successfully update the row, because they will create a new version.
Unlike optimistic locking, your query won't actually return an error when you try to read an outdated version. The database can still return data because it stores multiple versions of the row.
MVCC handles write concurrency similarly to optimistic locking: it throws an error and rolls back the transaction that tries to write to a row with a newer version or timestamp.
Solving The Booking Concert Issue
Let's revisit our first example: how do we solve the issue of overbooking seats in a concert? The solution is quite simple. The easiest way to keep the query performant is to use the Read Committed isolation level with some additions to the query.
The Read Committed isolation level ensures that no concurrent process is writing to the same row. Next, we'll add a filter to our query, remainingQty >= 1, which will ensure that there is always at least one seat available.
UPDATE seats SET remainingQty = remainingQty - 1 WHERE id = '1' AND remainingQty >= 1;
To validate whether the transaction is successful, we can count how many rows are affected by the query. If it’s 1, then the query is successful. If it’s 0, then it’s not, and we should throw an error.
Takeaways
In this article, we've explored the types of database locks and how they work. One important reminder is that we have only covered the concepts. Every database system has its own interpretation and implementation of these concepts, and understanding them is crucial if you want to master that specific database. However, the concepts discussed in this article should provide a solid foundation and make it easier for you to understand these implementations.


