



A retry mechanism is a critical component of many modern software systems. It allows our system to automatically retry failed operations to recover from transient errors or network outages. By automatically retrying failed operations, retry mechanisms can help software systems recover from unexpected failures and continue functioning correctly.
Today, we'll take a look at these topics:
- What is A Retry Pattern: What is a retry pattern? What is it for, and why do we need to implement it in our system?
- When to Retry Your Request: Only some requests should be retried. It's important to understand what kind of errors from the downstream service can be retried to avoid problems with business logic.
- Retry Backoff Period: When we retry the request to the downstream service, how long should we wait to send the request again after it fails?
- How to Retry?: We'll look at ways to retry from the basic to more complex.
What is A Retry Pattern
Retrying is an act of sending the same request if the request to downstream service failed. By using a retry pattern, you'll be improving the downstream resiliency aspect of your system. When an error happens when calling a downstream service, our system will try to call it again instead of returning an error to the upstream service.
So, why do we need to do it, exactly? Microservices architecture has been gaining popularity in recent decades. While this approach has many benefits, one of the downsides of microservices architecture is introducing network communication between services. Additional network communication leads to the possibility of errors in the network while services are communicating with each other (Read Fallacies of distributed computing). Every call to other services has a chance of getting those errors.
In addition, whether you're using monolith or microservices architecture, there is a big chance that you still need to call other services that are not within your company's internal network. Calling service within a different network means your request will go through more network layers and have more chance of failure.
Other than network errors, you can also get system errors like rate-limit errors, service down, and processing timeout. The errors you get may or may not be suitable to be retried. Let's head to the next section to explore it in more detail.
When to Retry Your Request
Although adding a retry mechanism in your system is generally a good idea, not every request to the downstream service should be retried. As a simple baseline, things you should consider when you want to retry are:
- Is it a transient error? You'll need to consider whether the type of errors you're getting is transient (temporary). For example, you can retry a connection timeout error because it's usually only temporary but not a bad request error because you need to change the request.
- Is it a system error? When you're getting an error message from the downstream service, it can be categorized as either: system error or application error. System error is generally okay to be retried because your request hasn't been processed by the downstream service yet. On the other hand, an application error usually means that something is wrong with your request, and you should not retry it. For example, if you're getting a bad request error from the downstream service, you'll always get the same error no matter how many times you've retried.
- Idempotency. Even when you're getting an error from the downstream service, there is still a chance it has processed your request. The downstream service could send the error after it has processed the main process, but another sub-process causes errors. Idempotent API means that even if the API gets the same request twice, it will only process the first request. We can achieve it by adding some id in the request that's unique to the request so the downstream service can determine whether it should process the request. Usually, you can differentiate this with the Request Method. GET, DELETE, and PUT are usually idempotent, and POST is not. But you need to confirm the API's idempotency to the service owner.
- The cost of retrying. When you retry your request to the downstream service, there will be additional resource usage. The additional resource usage can be in the form of additional CPU usage, blocked Thread, additional memory usage, additional bandwidth usage, etc. You need to consider this, especially if your service expects large traffic.
- The implementation cost of the retry mechanism. Many programming languages already have a library that implements a retry mechanism, but you still need to determine which request to retry. You can also create your retry mechanism or every system if you want to, but of course, this means that there will be a high implementation cost for the retry mechanism.
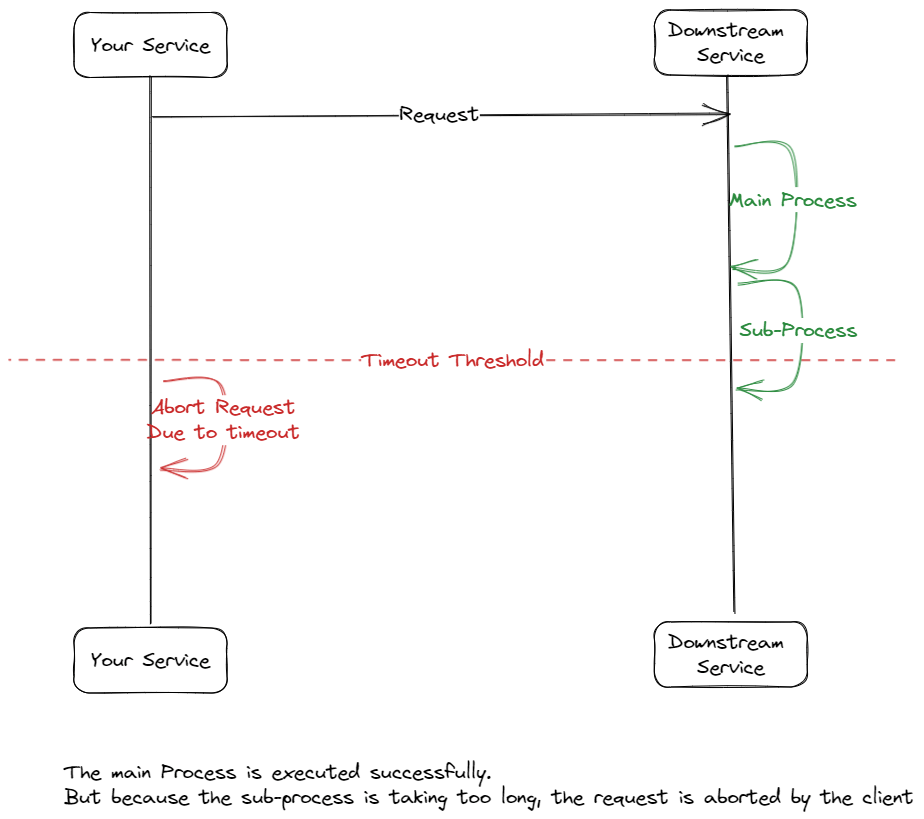
I've also compiled some common errors and whether or not they're suitable for retrying:
| Error | Retry(idempotent) | Retry(not idempotent) |
|---|---|---|
| Connection Timeout | Yes | Yes |
| Read Timeout | Yes | No |
| Circuit Breaker Tripped | Yes | Yes |
| 400: Bad Request | No | No |
| 401: Unauthorized | No | No |
| 404: Not Found | No | No |
| 429: Too Many Request | Yes (Longer backoff) | Yes (Longer backoff) |
| 500: Internal Server Error | Yes | Yes |
| 503: Service Unavailable | Yes | Yes |
Let's describe the errors shortly one by one
- Connection timeout: Your app failed to connect to the downstream service. Hence the downstream service isn't aware of your request, and you can retry it.
- Read timeout: The downstream app has processed your request but not returning any response for a long time.
- Circuit breaker tripped: This is an error if you use a circuit breaker in your service. You can retry this kind of error because your service hasn't sent its request to the downstream service
- 400 - Bad Request: This error means your request to the downstream service was flagged your request as a wrong request after validating it. You shouldn't retry this error because it will always return the same error if the request is the same.
- 401 - Unauthorized: You need to authorize before sending the request. Whether you can retry this error will depend on the authentication method and the error. But generally, you will always get the same error if your request is the same
- 429 - Too many requests: Your request is rate limited by the downstream service. You can retry this error, although you should confirm with the downstream service's owner how long your request will be rate limited.
- 500 - Internal Server Error: This means the downstream service had started processing your request but failed in the middle of it. Usually, it's okay to retry this error.
- 503 - Service Unavailable: The downstream service is unavailable due to downtime. It is okay to retry this kind of error.
Retry Backoff Period
When your request fails to the downstream service, your system will need to wait for some time before trying again. This period is called the retry backoff period.
Generally, there are three strategies for wait time between calls: Fixed Backoff, Exponential Backoff, and Random Backoff. All three of them have their advantages and disadvantages. Which one you use should depend on your API and service use case.
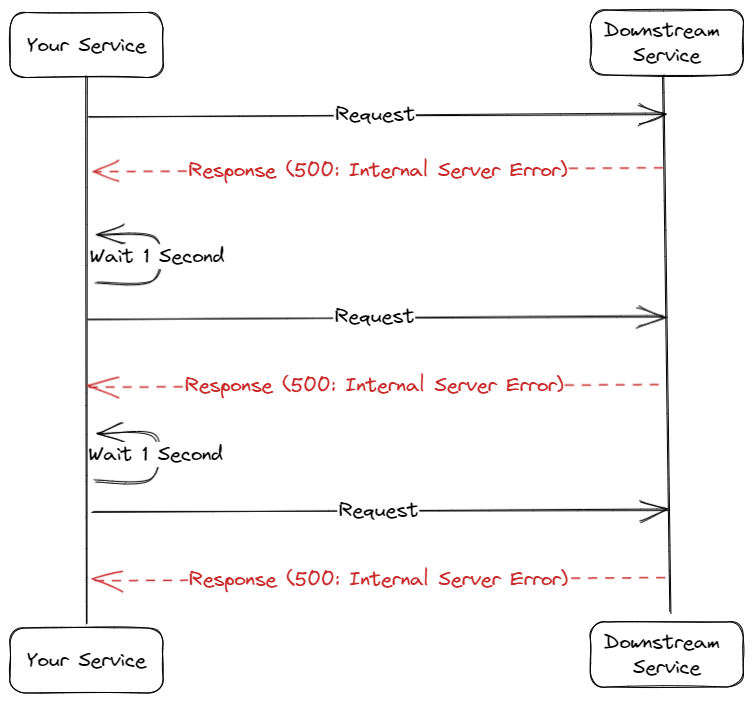
Fixed Backoff. Fixed backoff means that every time you retry your request, the delay between requests is always the same. For example, if you do a retry twice with a backoff of 5 seconds, then if the first call fails, the second request will be sent 5 seconds after. If it fails again, the third call will be sent 5 seconds after the failure.
A fixed backoff period is suitable for a request coming directly from the user and needs a quick response. If the request is important and you need it to come back ASAP, then you can set the backoff period to none or close to 0.
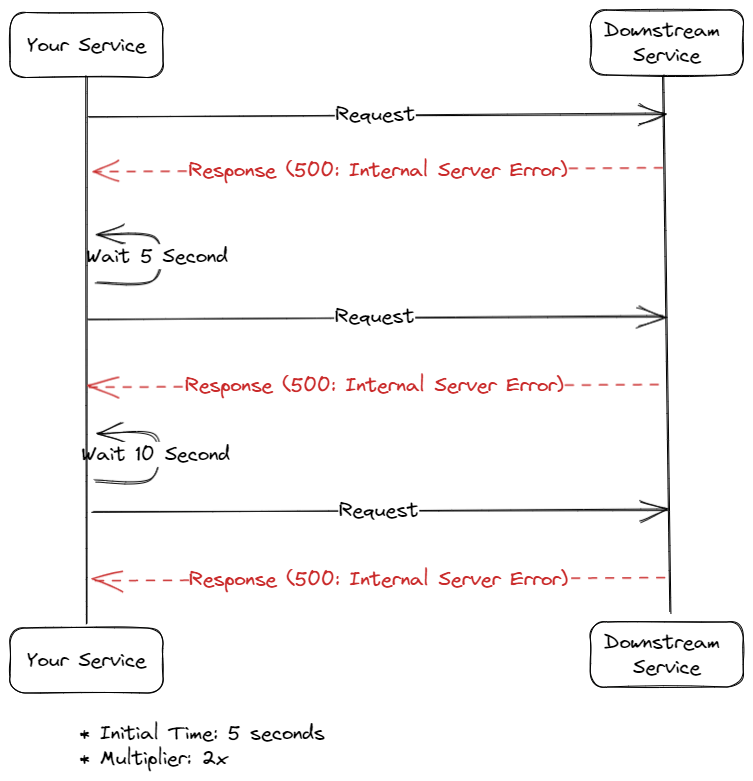
Exponential Backoff. When downstream service is having a problem, it doesn't always recover quickly. What you don't want to do when the downstream service is trying to recover is to hit it multiple times in a short interval. Exponential backoff works by adding some additional backoff time every time our service attempts to call the downstream service.
For example, we can configure our retry mechanism with 5-second initial backoff and add two as the multiplier every attempt. This means when our first call to the downstream service fails, our service will wait 5 seconds before the next call. If the second call fails again, the service will wait 10 seconds instead of 5 seconds before the next call.
Due to its longer interval nature, exponential backoff is unsuitable for retrying a user request. But it will be perfect for a background process like notification, sending email, or webhook system.
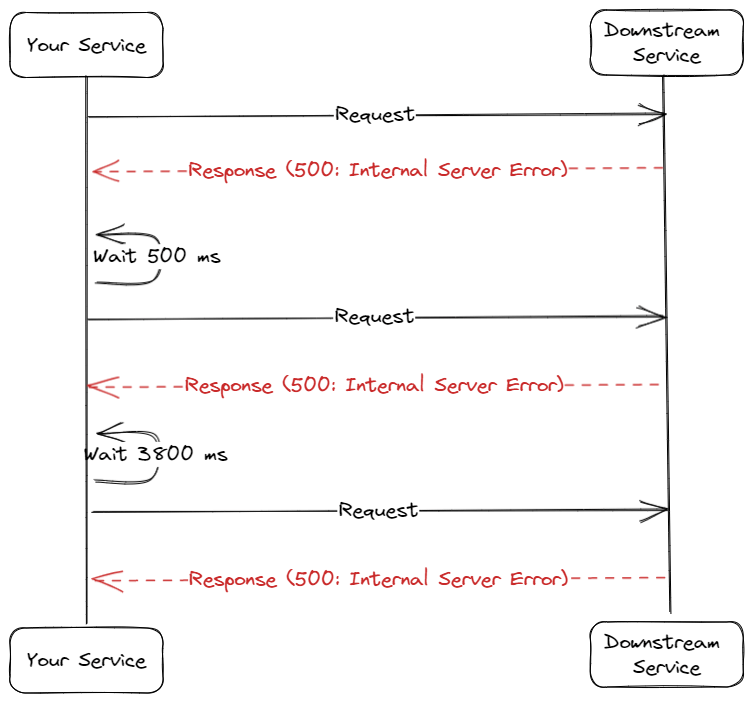
Random backoff is a backoff strategy introducing randomness in its backoff interval calculation. Suppose that your service is getting a burst of traffic. Your service then calls a downstream service for every request, and then you get errors from it because the downstream service gets overwhelmed by your request. Your service implements a retry mechanism and will retry the requests in 5 seconds. But there is a problem: when it's time to retry the requests, all of them will be retried at once, and you might get an error from the downstream service again. With the randomness introduced by the random backoff mechanism, you can avoid this.
A random backoff strategy will help your service to level the request to the downstream service by introducing a random value for retry. Let's say you configure the retry mechanism with 5 seconds interval and two retries. If the first call fails, the second one could be attempted after 500ms; if it fails again, the third one could be attempted after 3.8 seconds. If many requests fail the downstream service, they won't be retried simultaneously.
Where to store the retry state?
When doing a retry, you'll need to store the state of the retry somewhere. The state includes how many retries have been made, the request to be retried, and the additional metadata you want to save. Generally, there are three places you can use to store the retry state, which are:
Thread is the most common place to store the retry state. If you're using a library with a built-in retry mechanism, it will most likely use the Thread to store the state. The simplest way to do this is to sleep the Thread. Let's see some example in Java:
int retryCount = 0;
while (retryCount < 3) {
try {
thirdPartyOutboundService.getData();
} catch (Exception e) {
retryCount += 1;
Thread.sleep(3000);
}
}
The code above basically sleep the Thread when getting an exception and calling the process again. While this is simple, it has the disadvantage of blocking the Thread and making other processes unable to use the Thread. This method is suitable for a fixed backoff strategy with a low interval like processes that direct response to the user and need a response as soon as possible.
Messaging. We could use a popular messaging broker like RabbitMQ (delayed queue) to save a retry state. When you're getting a request from the upstream, and you fail to process it (it can be because of downstream service or not), you can publish the message to the delayed queue to consume it later (depending on your backoff).
Using messaging to save the retry state is suitable for a background process request because the upstream service can't directly get the response of the retry process. The advantage of using this approach is that it's usually easy to implement because the broker/library already supports the retry function. Messaging as a storage system of retry state also works well with distributed systems. One problem can happen is your service suddenly has a problem like downtime when waiting for the next retry. By saving the retry state in the messaging broker, your service can continue the retry after the issue has been resolved.
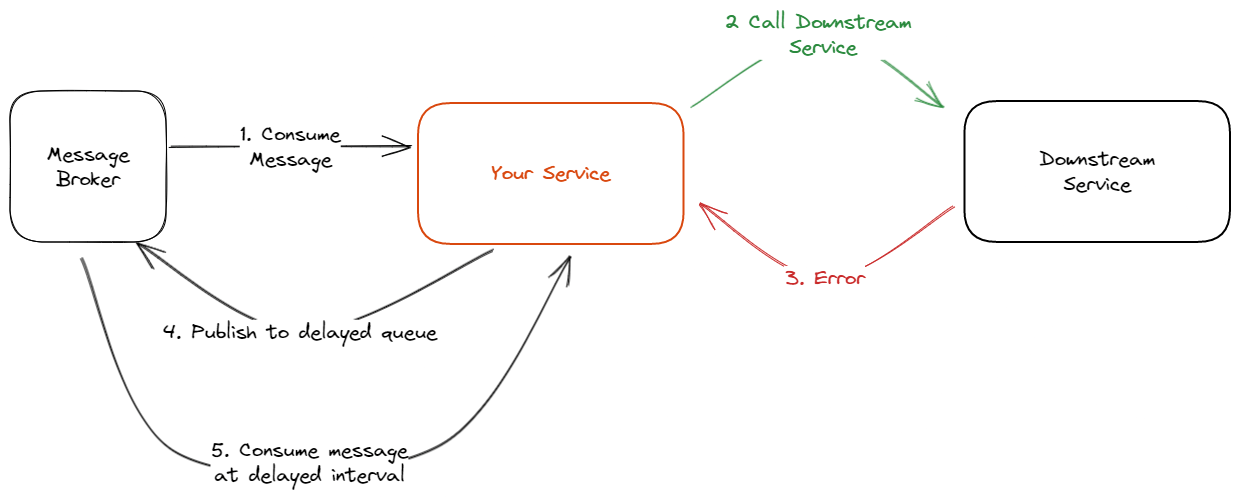
Database is the most customizable solution to store the retry state, either by using a persistent storage or an in-memory KV store like Redis. When the request to the downstream service fails, you can save the data in the Database and use a cron job to check the Database every second or minute to retry failed messages.
While this is the most customizable solution, the implementation cost will be very high because you'll need to implement your retry mechanism. You can either create the mechanism in your service with the downside of sacrificing a bit of performance when a retry is happening or make an entirely new service for retry purposes.
Takeaways
This article has explored what is and what aspects to consider when implementing a retry pattern.
You need to know what request and how to retry it.
If you do the retry mechanism correctly, you'll help with the user experience and reduced operation of the service you're building. But, if you do it incorrectly, you risk worsening the user experience and business error. You need to understand when the request can be retried and how to retry it so you can implement the mechanism correctly.
There is much more.
In this article, we've covered about retry pattern. This pattern increases the downstream resiliency aspect of a system, but there is more to the downstream resiliency. We can combine the retry pattern with a timeout(which we explored in this article) and circuit breaker to make our system more resilient to downstream failure. If you're interested, subscribe to the newsletter because we plan to write about that too.


