



If you want to create a simple one instead, you can read my other articles “Create a Simple Autocomplete With Elasticsearch“.
What is fuzzy logic
Fuzzy logic is a mathematics logic in which the truth of variables might be any number between 0 and 1. It is different with a Boolean logic that only has the truth values either 0 or 1.
In the Elasticsearch, fuzzy query means the terms in the queries don’t have to be the exact match with the terms in the Inverted Index.
To calculate the distance between query, Elasticsearch uses Levenshtein Distance Algorithm.
How to calculate distance using Levenshtein Distance Algorithm
Calculating a distance with Levenshtein Distance Algorithm is easy.
You just need to compare the first and second word character by character.
If the character is different, then you can add the distance between the words by one.
Let’s see an example, how to calculate the distance between the common typo word “Gppgle” with the correct word “Google”
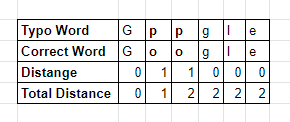
After we calculate the distance between “Gppgle” and “Google” with Levenshtein Distance Algorithm, we can see that the distance is 2.
Fuzzy Query in Elasticsearch
Handling typo in Elasticsearch with Fuzzy Query is also simple.
Let’s start with making an example of the typo word “Gppgle”.
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match" : {
"text": {
"query": "gppgle"
}
}
}
}'
Response
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
When we’re using normal Match Query, the Elasticsearch will analyze the query “gppgle” first before searching it into the Elasticsearch.
The only term in the inverted index is “google” and it doesn’t match the term “gppgle”. Therefore, the Elasticsearch won’t return any result.
Now, let’s try Elasticsearch’s fuzzy in Match Query
request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match" : {
"text": {
"query": "gppgle",
"fuzziness": "AUTO"
}
}
}
}'
response
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.19178805,
"hits": [
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "w8YOCXUBHf9qB4Apc0Cz",
"_score": 0.19178805,
"_source": {
"text": "google"
}
}
]
}
}
As you can see, with fuzzy, the Elasticsearch returned a response.
We’ve learnt in the before that “gppgle” and “google” have the distance of 2.
In the query, we inserted “fuzziness”:"AUTO" instead of a number. Why is it working?
Elasticsearch will determine what fuzziness distance is appropriate if we use “AUTO” value in the “fuzziness” field.
For 6 characters, the Elasticsearch by default will allow 2 edit distance.
“AUTO” fuzziness is preferable, but you can tune it with an exact number if you want to.
Now, let’s try with an exact number to prove that “gppgle” and “google” have a distance of 2.
gppgle and google with fuzziness 1
Request
curl --request POST \
--url 'http://localhost:9200/fuzzy-query/_doc/_search?explain=true' \
--header 'content-type: application/json' \
--data '{
"query": {
"match" : {
"text": {
"query": "gppgle",
"fuzziness": "1"
}
}
}
}'
Response
No Response
gppgle and google with fuzziness 2
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match" : {
"text": {
"query": "gppgle",
"fuzziness": "2"
}
}
}
}'
Response
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.19178805,
"hits": [
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "w8YOCXUBHf9qB4Apc0Cz",
"_score": 0.19178805,
"_source": {
"text": "google"
}
}
]
}
}
When we use “fuzziness”:"1", no result is returned by the Elasticsearch.
With “fuzziness”:"2", though, the Elasticsearch returned the document “google”.
This proves our previous distance calculation of “gppgle” and “google” with Levenshtein Distance Algorithm, in which the result is 2.
Two types of a fuzzy query in Elasticsearch
In the previous example, we use a fuzzy query as a parameter inside Match Query.
But there is another way to use the fuzzy feature, Fuzzy Query.
Seems to be the same! So, what’s the difference between them?
Before continuing, if you want to understand more about analyzer, you can read my other articles "Elasticsearch: Text vs. Keyword".
Fuzzy Query
Fuzzy Query works like just Term Query, the query to Elasticsearch is not analyzed and used raw to search the Inverted Index.
For example, let’s index one more document “Hong Kong”
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc \
--header 'content-type: application/json' \
--data '{
"text":"Hong Kong"
}'
Response
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "5sbKDXUBHf9qB4ApJUDr",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Let’s look on what terms the analyzer produces with Elasticsearch’s Analyze API.
Request
curl --request POST \
--url http://localhost:9200/_analyze \
--header 'content-type: application/json' \
--data '{
"analyzer": "standard",
"text": "Hong Kong"
}'
Response
{
"tokens": [
{
"token": "hong",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "kong",
"start_offset": 5,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
}
]
}
As you can see, the standard_analyzer produce two terms, “hong” and “kong”.
If you read my other article "Elasticsearch: Text vs. Keyword", you’d know that if we use a term query to search “Hong Kong” then we won’t get any result.
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"fuzzy" : {
"text": {
"value": "Hpng Kpng",
"fuzziness": "2"
}
}
}
}'
Response
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
This is because there is no term that has less than 2 edit distance with “Hong Kong” in the Elasticsearch.
Now, Let’s try Fuzzy Query with “Hpng”
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"fuzzy" : {
"text": {
"value": "HPng",
"fuzziness": "2"
}
}
}
}'
Response
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.60996956,
"hits": [
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "5sbKDXUBHf9qB4ApJUDr",
"_score": 0.60996956,
"_source": {
"text": "Hong Kong"
}
}
]
}
}
Term “Hpng” in the query and the term “hong” in the Elasticsearch have a distance of two.
Remember that the term queried and the term in the inverted index is case-sensitive, the distance “2” comes from the difference between “Hp” and “ho”.
Match Query with Fuzziness parameter
Match Query with fuzziness parameter is more preferable than Fuzzy Query. The analyzer in the query will analyze your query before searching it into the Inverted Index.
Let’s try the same query as we did in the Fuzzy Query’s section.
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match": {
"text": {
"query": "Hpng Kong",
"fuzziness": 2
}
}
}
}'
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match" : {
"text": {
"value": "HPng",
"fuzziness": "2"
}
}
}
}'
Response
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.762462,
"hits": [
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "5sbKDXUBHf9qB4ApJUDr",
"_score": 0.762462,
"_source": {
"text": "Hong Kong"
}
}
]
}
}
As expected, both queries returned a result!
The first query, “Hpng Kong” is analyzed into “hpng” and “kong”. Both terms “hpng” and “kong” exist in the Inverted Index.
“hpng” and “hong” matched with a distance of 1. While “kong” and “kong” match perfectly.
One thing to note if you plan to use Match Query is that every of the terms in the query will allow fuzziness.
We can try querying with “hggg kggg” which has an edit distance of 4 with “Hong Kong” using “fuzziness”:2.
Request
curl --request POST \
--url http://localhost:9200/fuzzy-query/_doc/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match": {
"text": {
"query": "hggg kggg",
"fuzziness": "2"
}
}
}
}'
Response
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "5sbKDXUBHf9qB4ApJUDr",
"_score": 1.2330425,
"_source": {
"text": "Hong Kong"
}
}
As you can see, the Elasticsearch returned a result.
This is because of the query “hggg kggg” is analyzed to terms “hggg” and “kggg” by the analyzer.
Both “hggg” and “kggg” respectively have the edit distance of 2 to “hong” and “kong” in the Elasticsearch.
Tuning the Fuzzy Query in Elasticsearch
You can tune the Fuzzy Query to match your use case.
In this section, I will write about the parameters that we can change in the query.
Fuzziness
Fuzziness is the heart of Fuzzy Query.
The value that we pass to this parameter is the maximum distance allowed.
There are two types of value that we can pass, an integer for exact maximum distance and “AUTO”.
The “AUTO” value allows the fuzziness in the query to be dynamic.
We can tune 2 parameters in the “AUTO” value and write it as “AUTO:[low],[high]”. The query will set fuzziness as 0 if the term length is below the low value. If the term length is between the low and high value, the query will set the fuzziness to 1. Last, If the term length is more than the high value, the query will set the fuzziness to 2.
The Elasticsearch will use 3 and 6 as the default if the low and high value is not determined.
Let’s use an example with a document “Fuzzy Query in Elasticsearch allows you to handle typos”.
We can try some queries to prove the mechanism of AUTO we described earlier.
“tp”: 1 edit distance from“to”.“Fyzzy”: 1 edit distance from“Fuzzy”.“Fyzyy”: 2 edit distance from“Fuzzy”.“Elastissearcc”: 2 edit distance from“Fuzzy”.“Elestissearcc”: 3 edit distance from“Fuzzy”.
After querying it, these queries produced a result:
“Fyzzy”“Elastissearcc”
The queries don’t:
“tp”“Fyzyy”“Elestissearcc”
Transpositions
transpositions will allow your query to calculate the transpositions of two adjacent characters (ab -> ba) as 1 distance.
For example, if we set the transpositions to true, we will get a result if we query with “leasticsearcc”.
But if we set it as false, there will be no result from the Elasticsearch.
Request
{
"query": {
"fuzzy": {
"text": {
"value": "leasticsearcc",
"fuzziness": "AUTO",
"transpositions": true
}
}
}
}
Response
{
"_index": "fuzzy-query",
"_type": "_doc",
"_id": "AsawDnUBHf9qB4ApNUFh",
"_score": 0.5491282,
"_source": {
"text": "Fuzzy Query in Elasticsearch allows you to handle typos"
}
}
The Elasticsearch defaults the transpositions setting to true.
We can’t set this setting to the Match Query. The Match Query will always calculate transpositions as 1 distance.
Max Expansions
max_expansions will determine the maximum result you get from your query.
If you set the max_expansions to 1 and there is 2 document in the Elasticsearch that are appropriate to your query, the Elasticsearch will only return 1.
Note that max_expansions applies to shard level. So if you have many shards in the Elasticsearch, even if you set the max_expansion to 1, the query might return more results.
The default value for max_expansions is 50.
Prefix Length
prefix_length is the number of prefix characters that is not considered in fuzzy query.
For example, if we set the prefix_length to 1, we won’t get any result if we query “llasticsearch”.
The prefix_length setting defaults to 0.
Rewrite
You can change rewrite parameter if you want to change the scoring of the results.
You can find more information about the rewrite parameter in the Elasticsearch documentation.
Conclusion
Handling a typo in Elasticsearch is very easy and can improve the user’s experience.
The simplest way to handle a typo is to just add “fuzziness”:"AUTO" in your Match Query.
If you want to tune the Query, there are some parameters that you can change with the “fuzziness” being the most important.
Thank you for reading until the end!
Stay tune to my other articles about Elasticsearch!


