



Elasticsearch has been used more and more in the software engineering, data and DevOps fields. In this post I will write about the basics of elasticsearch from developer perspective.
So what is the definition of elasticsearch? according to elasticsearch’s website:
Elasticsearch is a distributed, open source search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene and was first released in 2010 by Elasticsearch N.V. (now known as Elastic). Known for its simple REST APIs, distributed nature, speed, and scalability, Elasticsearch is the central component of the Elastic Stack, a set of open source tools for data ingestion, enrichment, storage, analysis, and visualization. Commonly referred to as the ELK Stack (after Elasticsearch, Logstash, and Kibana), the Elastic Stack now includes a rich collection of lightweight shipping agents known as Beats for sending data to Elasticsearch.
Writing to Elasticsearch
What happens if you insert a document to an index in elasticsearch? If you’re familiar with SQL and NoSQL databases, then you should know that there are many processes that happen when you insert a document into the database, one of reason of the processing is to optimize query speed. Same as other databases, there are also many processes that happen when you insert a document to elasticsearch, like determining field type, analyzing the text and in memory buffer system, but before that we need to know the most important thing when writing a data to elasticsearch, the Inverted Index
Inverted Index
Inverted index is the main thing that makes querying to elasticsearch blazingly fast. It is a data structure that maps term with its position in documents. For example when you are writing documents to elasticsearch like the following:
Document 1: “Elasticsearch is fast”
Document 2: “I want to learn elasticsearch”
Here is what it would like in the inverted index:
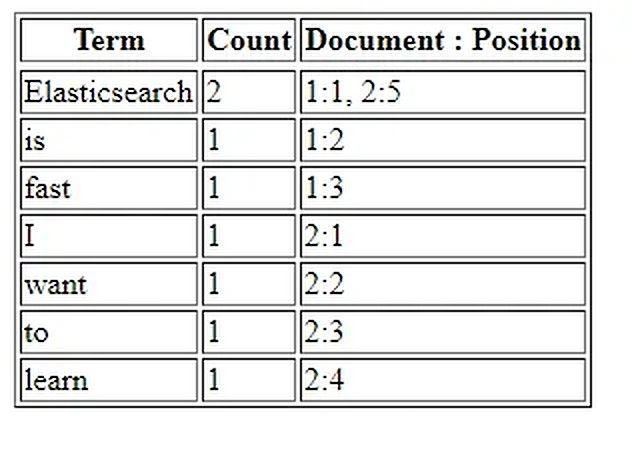
Now, every time you want to search “Elasticsearch” word then elasticsearch will looks into the term “Elasticsearch” in the inverted index and get the documents number from it.


