



Have you ever spent hours trying to debug an error that randomly appears for some users but vanishes when you try to reproduce it? It’s like chasing a ghost—frustrating and elusive. Welcome to the tricky world of race conditions, one of the sneakiest bugs you'll encounter, especially in distributed systems.
A race condition occurs when multiple processes attempt to access and modify the same resource concurrently, resulting in unexpected behavior or data corruption. It can lead to severe financial losses, security vulnerabilities, and significant damage to your organization's reputation.
Race conditions are particularly challenging in distributed systems because they're difficult to reproduce locally or in testing environments. Typically, these issues surface in production, making root-cause analysis challenging.
In this article, we'll explore:
- What is a Race Condition? Let’s dive into what a race condition really is—and how it can lead to serious consequences, including financial losses. We’ll walk through a real-world example to make it clear.
- How Do Race Conditions Happen? What situations or patterns open the door to race conditions? In this section, we’ll break down the common causes you should watch out for to stay ahead of the problem.
- Strategies to Avoid Race Conditions: Prevention is better than cure. Here, we’ll explore techniques and best practices to minimize the risk of race conditions in your systems.
- How to Detect and Fix Race Conditions: Even with the best efforts, bugs can slip through. So what happens when a race condition hits production? We’ll cover how to detect and troubleshoot it effectively.
- Bank Case Example: Let’s walk through a race condition scenario in a banking system—where two concurrent transactions can lead to incorrect balances—and see how we can prevent and fix it with the right approach.
How Do Race Conditions Occur?
As mentioned earlier, race conditions occur when multiple processes access and modify the same shared resource at the same time. They typically happen in multi-threaded applications or distributed systems, where multiple operations run concurrently and may interact with the same data—leading to unpredictable results if not properly synchronized.
Example: Banking Application
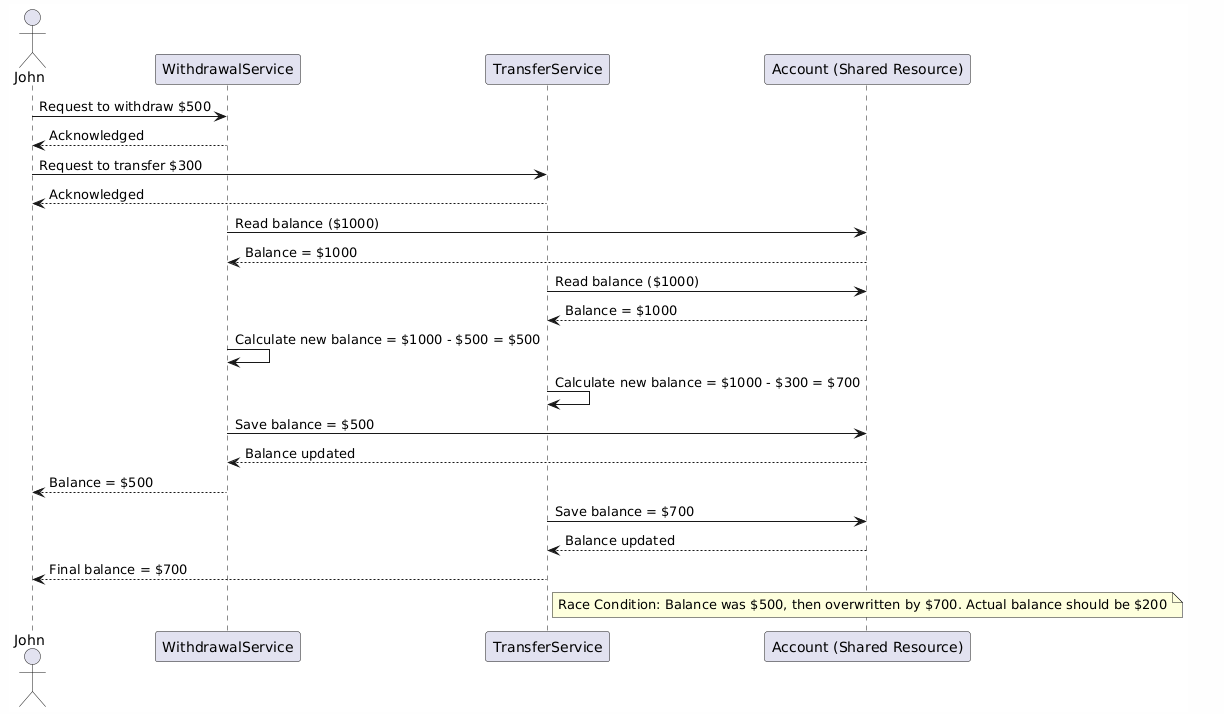
Consider a banking application with a customer named John, who has $1000 in his account. John simultaneously initiates two transactions:
- Withdraw $500.
- Transfer $300 to a friend.
Ideally, John's balance after both transactions should be $200. However, due to a race condition, his balance shows $700. This happens because both transactions accessed and modified the balance simultaneously.
Risks of Race Conditions:

Data Inconsistency
If multiple tables are involved (e.g., balance and history), race conditions can cause mismatched data that accumulates over time—making it hard to fix later.
Security Vulnerabilities
As seen in the example, an attacker could exploit the inconsistency to gain financial advantage—leading to real losses.
Resource Crashes
Race conditions can trigger deadlocks. Without retry limits, blocked threads may exhaust system resources and crash the app.
Poor User Experience
Users may see incorrect data, failed actions, or random errors—damaging trust and usability.
Strategies to Avoid Race Conditions
We'll split section into two: avoiding race conditions for multi-threaded application and avoiding it for distributed systems.
Multi-threaded Applications
Preventing race conditions in multi-threaded applications is generally easier than in distributed systems. That said, many distributed services are also multi-threaded under the hood—so these techniques still apply.
- Minimize Shared Variables: Reducing shared states across threads significantly decreases the chances of a race condition.
- Mutex Locks: Mutex locks ensure atomic access to shared resources, allowing only one thread to access the resource at a time.
Mutex Locks example:
package main
import (
"fmt"
"sync"
)
// Counter is a thread-safe counter with a mutex to prevent race conditions.
type Counter struct {
mu sync.Mutex // Mutex to synchronize access to the value.
value int // The actual counter value.
}
// Increment increases the counter value by 1 in a thread-safe manner.
func (c *Counter) Increment() {
c.mu.Lock() // Acquire the lock before accessing the value.
defer c.mu.Unlock() // Ensure the lock is released after the function completes.
c.value++ // Safely increment the counter.
}
func main() {
var wg sync.WaitGroup // WaitGroup to wait for all goroutines to finish.
counter := Counter{} // Initialize the Counter.
// Launch 1000 goroutines to increment the counter concurrently.
for i := 0; i < 1000; i++ {
wg.Add(1) // Increment the WaitGroup counter.
go func() {
defer wg.Done() // Decrement the WaitGroup counter when the goroutine completes.
counter.Increment() // Safely increment the counter.
}()
}
wg.Wait() // Wait for all goroutines to finish.
fmt.Println("Final Counter Value:", counter.value) // Print the final counter value.
}
Distributed Systems
Preventing race conditions in distributed systems is more complex than in multi-threaded apps. Local mutexes won’t help here—each instance runs independently, so the same operation could happen in parallel across nodes.
Locking across distributed systems is also slower and can impact performance. That’s why we need different strategies—like distributed locks, idempotency, and optimistic locking—to handle race conditions at scale.
Database Locks (ACID Transactions):
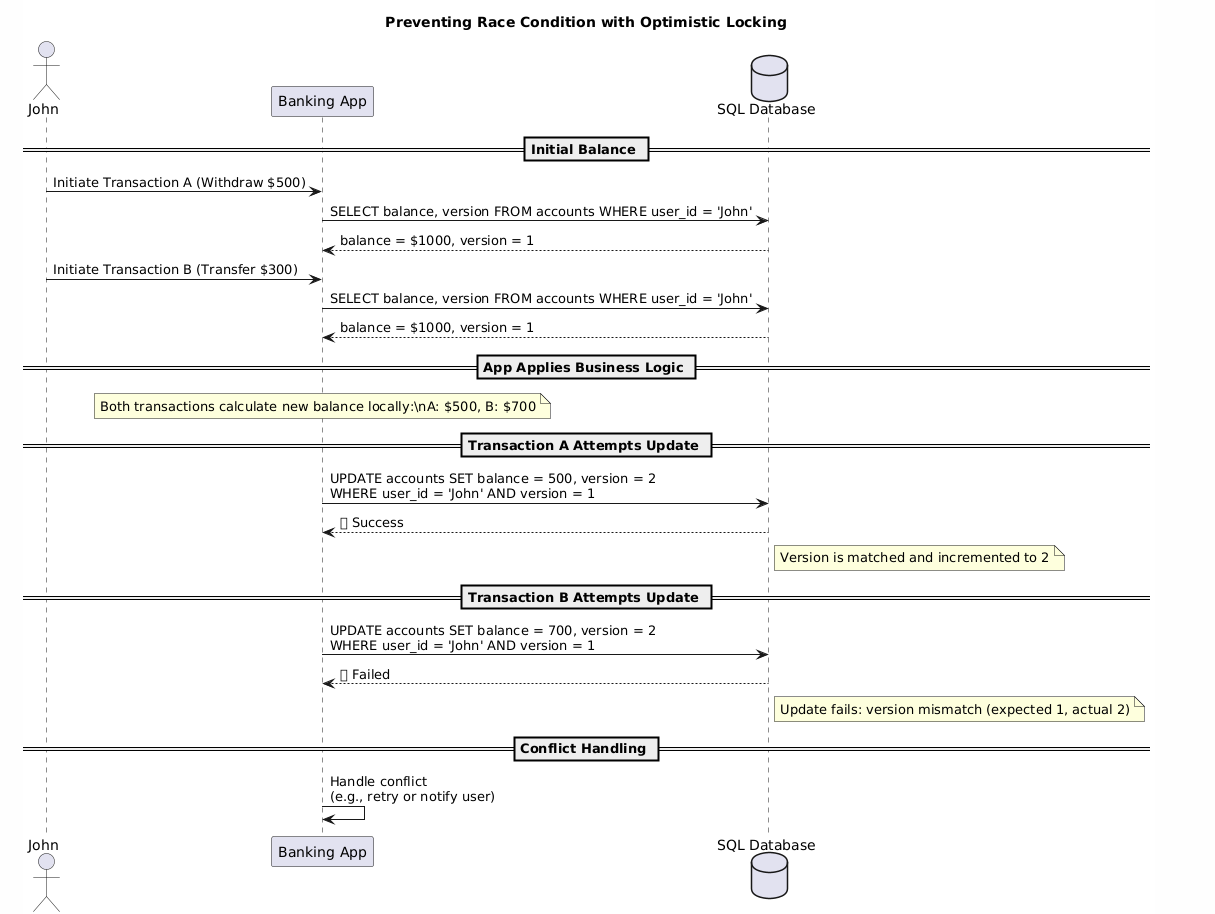
- Utilize transactional features of SQL databases to ensure only one transaction can update a record at a time, automatically rolling back conflicting transactions.
- Be cautious about asynchronous calls within transactions as they might cause additional consistency issues.
If you want to dive deeper into how database locks work, check out my other article: Understanding Database Locks. It covers optimistic vs. pessimistic locking, transaction isolation levels, and how they help prevent race conditions in database systems.
Redis Distributed Locks:
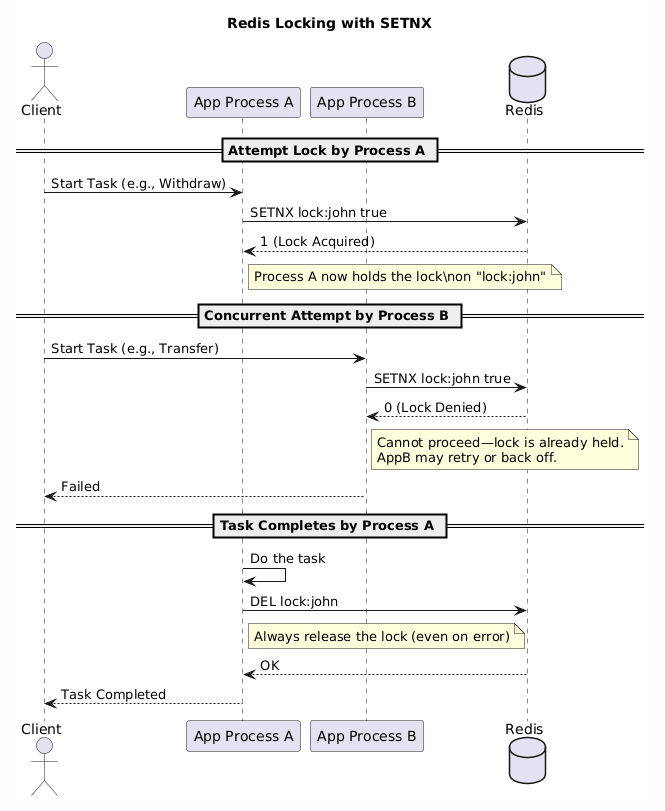
- Great for Locking: Redis is fast and single-threaded—only one process can modify a key at a time.
SETNX key valuesets the key only if it doesn’t exist.- Use
SETNX:- Returns
1if lock acquired,0if it’s already taken.
- Returns
- Always Release the Lock:
- Delete the key after your process (even on error—use
finally) to avoid stale locks.
- Delete the key after your process (even on error—use
- Trade-offs:
- Adds system complexity and a new dependency.
- If you're already using DB locks and they’re sufficient—stick with them.
- Use Redis locks when you need stronger concurrency guarantees.
Partitioning in Message Queues:
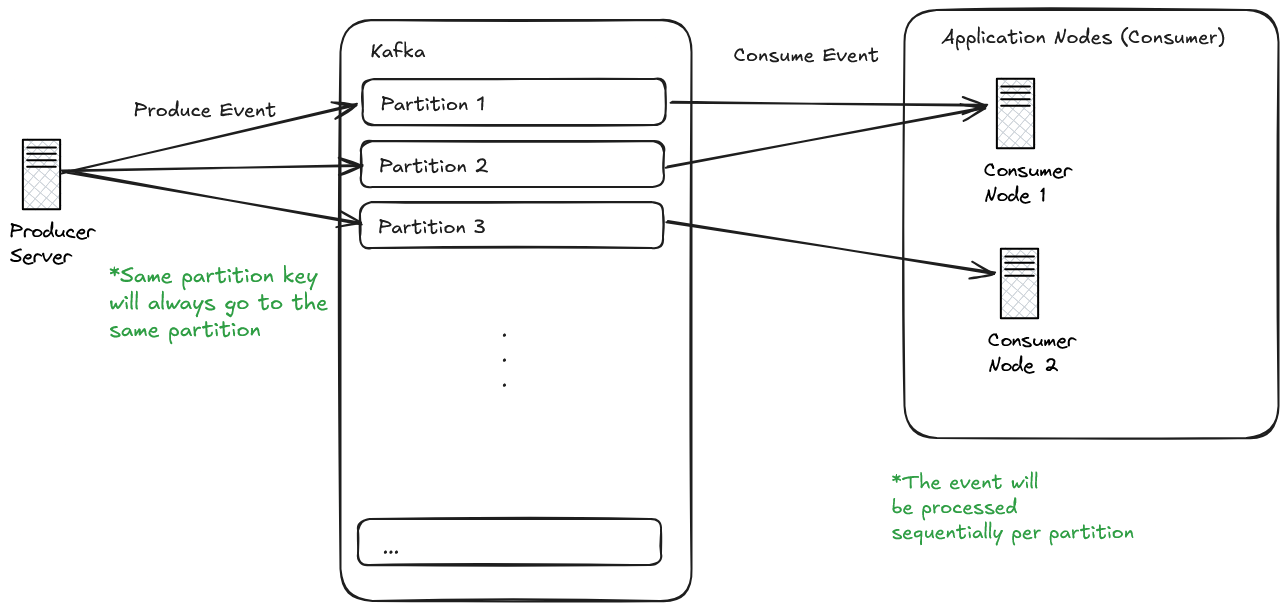
- Set Partition Key Properly:
- Kafka groups messages by partition key.
- Events with the same key go to the same partition, preserving order.
- Concurrency Control:
- Each partition is processed by one consumer instance at a time.
- This prevents concurrent processing of messages with the same key.
- Avoid Async in Handlers:
- Asynchronous operations can bypass Kafka’s ordering guarantees.
- Keep processing synchronous if order and consistency matter.
Idempotency:
- What Is Idempotency?
- An idempotent API returns the same result, even if called multiple times.
- Why It Helps:
- Prevents duplicate operations (e.g., double updates or creates).
- Reduces impact of retries or concurrent requests.
- Design Tip:
- Use idempotency keys or consistent request logic to ensure safe repeated calls.
You can learn more about idempotency in my other article on designing retry mechanisms. It dives into building resilient systems with retries and explains how idempotency ensures data consistency—even when operations are repeated.
Detecting and Fixing Race Conditions
We’ve covered how to prevent race conditions—but how do you actually detect them when they happen?

Proper Logging
While logging alone won’t catch race conditions, it’s essential for diagnosing them. With detailed logs—especially around critical sections or shared resources—you’ll have the visibility needed to trace odd behaviors and identify concurrency issues.
[INFO] 2025-04-19T10:42:00.123Z [txn-1] Starting transaction: withdraw $500 from userId=123
[DEBUG] 2025-04-19T10:42:00.124Z [txn-1] Fetching current balance for userId=123
[INFO] 2025-04-19T10:42:00.126Z [txn-1] Current balance: $1000
[DEBUG] 2025-04-19T10:42:00.128Z [txn-1] New balance after withdraw: $500
[INFO] 2025-04-19T10:42:00.130Z [txn-1] Attempting to update balance in DB
[INFO] 2025-04-19T10:42:00.131Z [txn-2] Starting transaction: transfer $300 from userId=123 to userId=456
[DEBUG] 2025-04-19T10:42:00.132Z [txn-2] Fetching current balance for userId=123
[INFO] 2025-04-19T10:42:00.133Z [txn-2] Current balance: $1000
[DEBUG] 2025-04-19T10:42:00.134Z [txn-2] New balance after transfer: $700
[INFO] 2025-04-19T10:42:00.135Z [txn-2] Attempting to update balance in DB
[INFO] 2025-04-19T10:42:00.136Z [txn-1] Balance update success. Commit transaction.
[ERROR] 2025-04-19T10:42:00.137Z [txn-2] Balance update failed due to conflict (expected balance version=1, actual=2)
[INFO] 2025-04-19T10:42:00.138Z [txn-2] Rolling back transaction due to conflict
Monitoring for Data Inconsistencies
Set up monitoring or periodic jobs to detect symptoms of race conditions:
- Mismatched balances vs. transaction history.
- Duplicate records or skipped entries.
- Unexpected error spikes.
Even if the root cause isn’t clear immediately, spotting the effect early helps you contain the issue.
Anomaly Detection via Metrics
Track key metrics such as:
- Frequency of retries
- Spike in failed operations
- Inconsistencies in resource usage (e.g., memory, CPU, DB locks)
Unusual patterns—especially those that correlate with traffic surges—can be an early sign of race conditions under load.
Concurrency Testing
- Unit-Level Testing
- Go Example: Use
go test -race ./...to detect unsynchronized access to shared memory. - Other languages may require third-party tools or frameworks.
- Go Example: Use
- End-to-End Testing
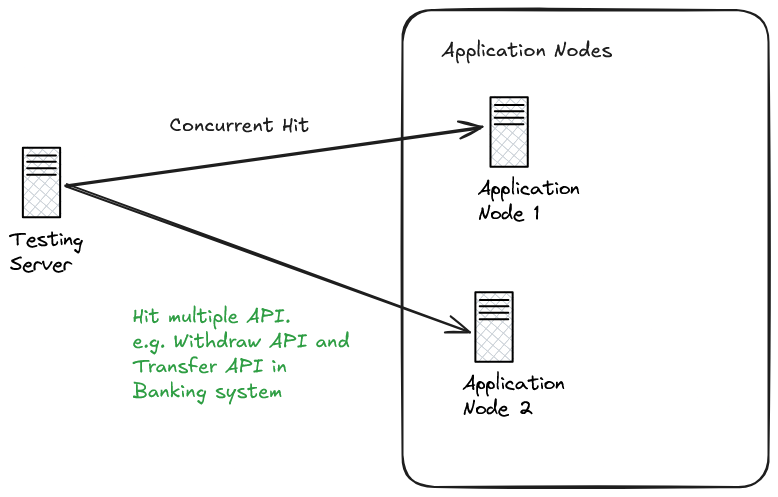
- Simulate real-world concurrent scenarios by sending simultaneous requests.
- Assert outcomes to catch inconsistencies or unexpected side effects.
- Ensure APIs are idempotent to make the test reliable and repeatable.
- You can use tools like K6 and JMeter for end-to-end concurrent testing.
Case Study: Solving the Banking Application Race Condition
Let's revisit the banking example to see how we can effectively resolve the race condition:
- Scenario: John has $1000 in his account and simultaneously initiates a withdrawal of $500 and transfers $300 to a friend.
Solutions we can implement:
- Database Locking: Wrap balance updates within database transactions to ensure atomicity. If concurrent transactions conflict, the database automatically rolls back one, maintaining consistency.
- Redis Distributed Locking: Use Redis locks (
SETNX) to ensure only one transaction modifies the balance at a time, providing robust concurrency control. - Idempotent API Design: Ensure API endpoints can safely handle repeated requests without negative consequences.
Outcome: Implementing these strategies ensures that John's balance accurately updates to $200, effectively eliminating the race condition.
Key Takeaways
In this article, we've explored various strategies to detect and address race conditions in your systems:
- Implement Comprehensive Logging: While logging alone won't catch race conditions, it's essential for diagnosing them. With detailed logs—especially around critical sections or shared resources—you'll have the visibility needed to trace odd behaviors and identify concurrency issues.
- Monitor for Data Inconsistencies: Set up monitoring or periodic jobs to detect symptoms of race conditions, such as mismatched balances vs. transaction history, duplicate records, or unexpected error spikes.
- Utilize Anomaly Detection via Metrics: Track key metrics like the frequency of retries, spikes in failed operations, and inconsistencies in resource usage (e.g., memory, CPU, DB locks). Unusual patterns, especially those correlating with traffic surges, can be early indicators of race conditions under load.
- Conduct Concurrency Testing: Employ both unit-level testing (e.g., using
go test -race ./...in Go) and end-to-end testing to simulate real-world concurrent scenarios. Ensure APIs are idempotent to make tests reliable and repeatable.
By proactively implementing these strategies, you can enhance the reliability and consistency of your applications, ensuring a smoother experience for your users.


