



When you're building complex microservices that handle a lot of traffic, failure becomes a normal part of the system—especially in environments where teams push changes weekly, or even multiple times a week.
Resiliency plays a critical role in software design. A resilient system can isolate failures and recover gracefully. Take a travel commerce example: if one airline's server goes down, that failure shouldn't impact other unrelated flows. Ideally, the system should recover on its own.
A Circuit Breaker is a commonly used mechanism to improve a system’s resiliency. Inspired by electrical circuit breakers, it behaves similarly—in electricity, when a breaker detects a voltage spike, it trips and stops the current to protect appliances. In software, when a downstream service behaves abnormally, a circuit breaker can trip and stop requests from going through.
This behavior provides two main benefits: containing the incident to only the affected part of the system and supporting self-healing. In this article, we’ll cover:
- Understanding the Circuit Breaker: A deeper look into what it is and how it prevents cascading failures.
- Why Use a Circuit Breaker: When and why to implement one in your architecture.
- How Circuit Breakers Work: The internal states and configurations.
- Implementing a Circuit Breaker: A hands-on example using Hystrix.
- Best Practices: Practical tips and gotchas to watch out for.
Understanding The Circuit Breaker
As mentioned, a circuit breaker works like an electrical circuit breaker—it stops traffic to a failing downstream dependency. This is especially helpful when your service has multiple downstream dependencies and flows that are unrelated. If one dependency fails, you don’t want the others to be affected. Circuit breakers help by cutting off the connection entirely, saving resources.
Think of a building’s electrical system: if there’s a voltage spike, the breaker trips to prevent damage—or even a fire. In software, the equivalent would be your service crashing because it’s overloaded with slow or failing requests from a downstream service. Without a circuit breaker, a single failure could spiral into a full outage.
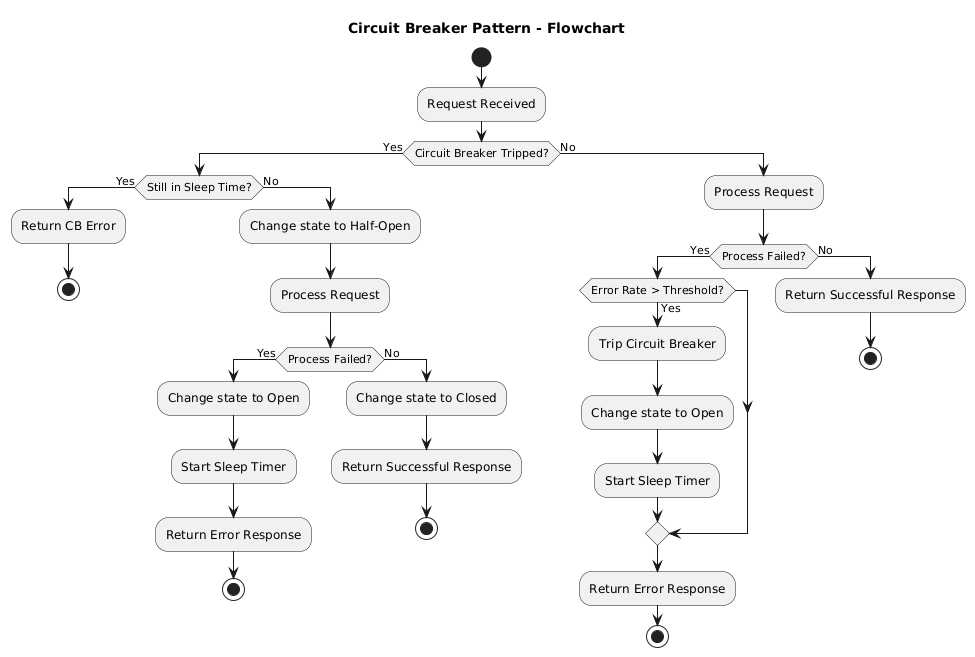
When a circuit breaker trips:
- It goes into the Open state, rejecting all requests to the downstream service. The error is returned immediately.
- After a timeout, it moves into the Half-Open state, allowing a limited number of requests to test if the downstream service has recovered.
- If those requests succeed, it transitions back to Closed, and all traffic is allowed again. If they fail, it trips back to Open.
Why Use a Circuit Breaker?
Now that we know what a circuit breaker is, why use it? What happens if we don’t?
Anytime your service calls another service, it uses resources—CPU, memory, threads, connections. If the downstream service is down or very slow, your service will waste resources waiting. In high-traffic environments, this can lead to resource exhaustion and eventually cause your own service to go down.
Imagine a travel commerce site where one airline's API is down. Users should still be able to see and purchase flights from other airlines. But if your system keeps making slow calls to the failing airline API, it could eat up all your resources and take down the whole service. This leads to cascading failures across systems.
Even if your service doesn’t crash, using a circuit breaker can help with:
- Not overloading the downstream service during incidents.
- Failing fast, which improves user experience and prevents unnecessary load on your own service.
Let’s say your service has a circuit breaker and the client calling your service doesn’t. By returning a fast error instead of making a slow failing call, you help prevent cascading failures further upstream. Bonus: your users won’t have to wait several seconds for a timeout—they’ll get an immediate error, which is often a better experience.
How Circuit Breakers Work
Now that we’ve seen the value of a circuit breaker, let’s look at how it works in more detail.
Circuit breakers typically have three states:
- Closed – Everything is working. All requests pass through to the downstream dependency.
- Open – The breaker has tripped. No requests are allowed through.
- Half-Open – A trial state after some timeout. Some requests are allowed to test whether the downstream is back.
Let's use this chart to better visualize the state flow of the circuit breaker:
You can refer to this diagram for better understanding on how the state changes:
Key Configuration Options
- Failure Rate Threshold: Determines when the breaker should trip. You might configure it to trip if more than 50% of the last 100 requests fail.
- Reset Timeout: How long the breaker should stay open before trying to move to half-open. Set it too low and you risk overloading the service again. Set it too high and recovery might be delayed unnecessarily.
- Half-Open Test Requests: The number of requests to allow during half-open state before deciding whether to close or re-open the breaker.
These configuration options may differ slightly depending on the library you use, but they’re commonly supported. Many circuit breaker libraries also let you configure timeouts and concurrency limits. Make sure to check your library’s documentation for full capabilities.
Circuit Breaker in Action (with Hystrix in Go)
Let’s walk through an example using the Hystrix library in Go. Hystrix Circuit Breaker library was developed by Netflix and is available in various languages. It also provides a built-in dashboard to visualize the circuit breaker’s state.
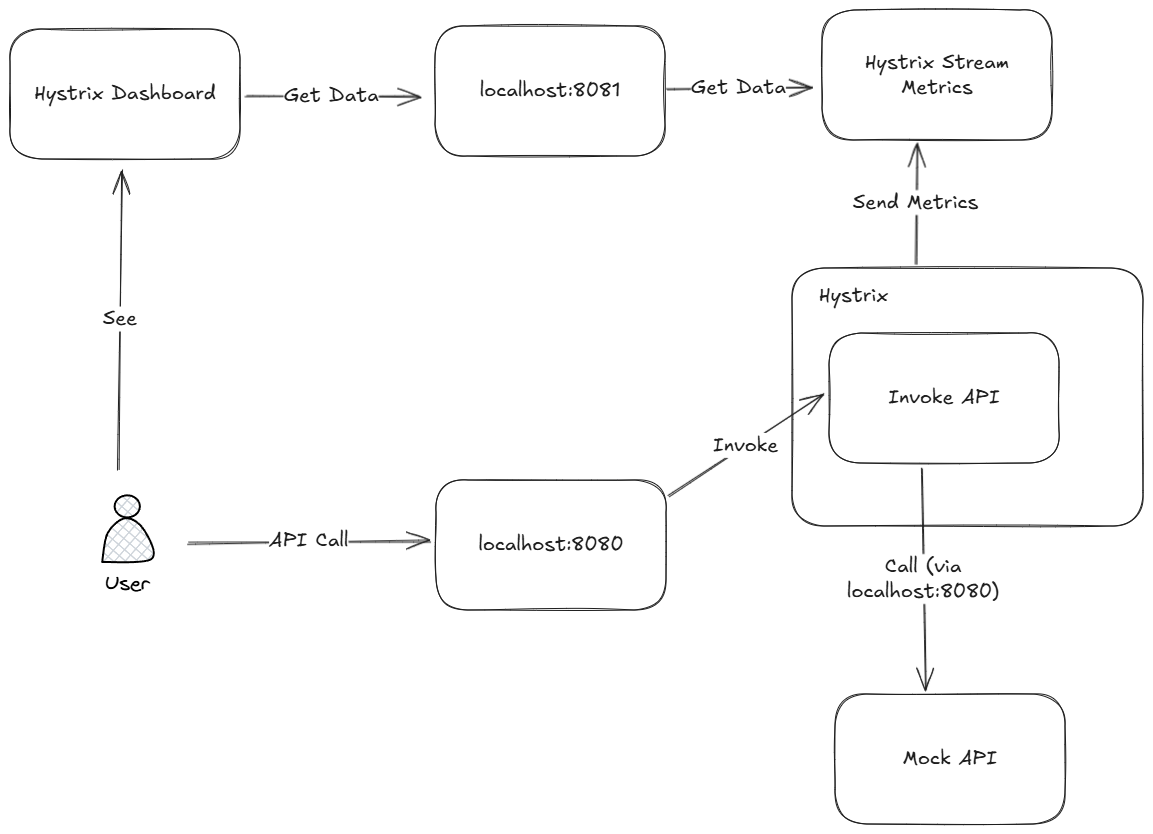
This is a simple diagram showing what we will build in this section:
Setup
We’ll create two APIs:
- A mock API that always returns an error (to simulate a faulty dependency).
- An invoke API that calls the mock API with a Hystrix circuit breaker.
hystrix.ConfigureCommand("mock_api_call", hystrix.CommandConfig{
Timeout: 1000,
MaxConcurrentRequests: 100,
RequestVolumeThreshold: 5,
SleepWindow: 5000,
ErrorPercentThreshold: 50,
})
The "mock_api_call" identifier allows multiple breakers with different configs in a service.
Then we start the Hystrix stream handler, which will allow us to connect a dashboard to visualize circuit breaker behavior:
// Start Hystrix stream handler
hystrixStreamHandler := hystrixgo.NewStreamHandler()
hystrixStreamHandler.Start()
go func() {
log.Println("Starting Hystrix stream handler on port 8081...")
if err := stdhttp.ListenAndServe(":8081", hystrixStreamHandler); err != nil {
log.Printf("Error starting Hystrix stream handler: %v", err)
}
}()
Mock API
// HandleMockAPI handles requests to the mock API endpointfunc (h *Handler) HandleMockAPI(w http.ResponseWriter, r *http.Request) {
log.Println("Mock API called")
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
}
This API always returns a 500 error to simulate failure.
Invoke API
// HandleInvoke handles requests to the invoke endpointfunc (h *Handler) HandleInvoke(w http.ResponseWriter, r *http.Request) {
output := make(chan string, 1)
log.Println("Calling mock API")
errors := hystrix.Go("mock_api_call", func() error {
log.Println("Calling mock API")
result, err := h.apiClient.CallMockEndpoint()
if err != nil {
return err
}
output <- result
return nil
}, func(err error) error {
// Fallback function
output <- fmt.Sprintf("Fallback: %v", err)
return nil
})
select {
case result := <-output:
fmt.Fprintln(w, result)
case err := <-errors:
log.Printf("Error: %v", err)
http.Error(w, "Error processing request", http.StatusInternalServerError)
}
}
What this API will do is:
- Handles an HTTP request when someone calls the endpoint.
- Tries to call a mock API using
h.apiClient.CallMockEndpoint(). - Wrap Hystrix on the API call. Notice that we're using the
mock_api_callcommand we've setup before - If the API call works, it sends the result to the user.
- If the API call fails, it runs a fallback function and sends a fallback message instead. Which contain the error happened so we can differentiate whether the error is from the mock API or from the tripped circuit breaker.
When you hit the invoke API a few times, you’ll start to see this response:
Fallback: hystrix: circuit open
This means the circuit breaker has tripped and is blocking further calls to the mock API.
In the log, you will see:
2025/04/03 14:25:18 Invoke API called
2025/04/03 14:25:18 Calling mock API
2025/04/03 14:25:18 Mock API called
2025/04/03 14:25:18 Invoke API called
2025/04/03 14:25:18 Calling mock API
2025/04/03 14:25:18 Mock API called
2025/04/03 14:25:19 Invoke API called
2025/04/03 14:25:19 Calling mock API
2025/04/03 14:25:19 Mock API called
2025/04/03 14:25:19 Invoke API called
2025/04/03 14:25:19 Calling mock API
2025/04/03 14:25:19 Mock API called
2025/04/03 14:25:19 Invoke API called
2025/04/03 14:25:19 Calling mock API
2025/04/03 14:25:19 Mock API called
2025/04/03 14:25:20 Invoke API called
Notice that when the circuit is open, the actual call to the mock API is skipped entirely, proving that the breaker is doing its job.
Monitoring with Hystrix Dashboard
You can visualize how the Hystrix is running by running Hystrix dashboard in Docker:
docker run --rm -p 7979:7979 --name hystrix-dashboard steeltoeoss/hystrix-dashboard
Then point the dashboard to:http://host.docker.internal:8081 (use this if your app is running outside Docker).
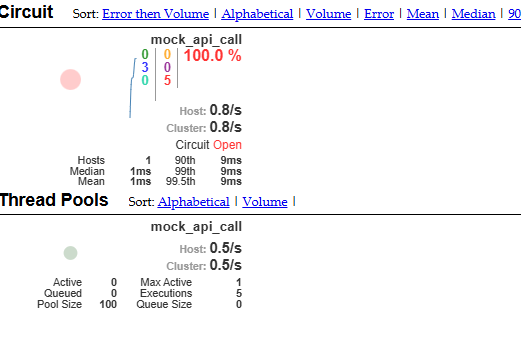
The red number indicates the count of errors returned by the Invoke API (or more specifically, by the code wrapped in the Hystrix function). The purple number indicates how many requests were short-circuited. In this case, I hit the Invoke API 8 times—5 of which reached the mock API and returned an internal server error (ISE), while 3 were short-circuited and returned an error without hitting the mock API.
You can check the full code in: https://github.com/brilianfird/hystrix-circuit-breaker-demo
Best Practices When Using Circuit Breakers
You now understand how a circuit breaker works and how to configure it. But how should you tune it in a real-world system?
Check your monitoring to determine the right circuit breaker configuration
The best way to set the circuit breaker values is by understanding how your service interacts with its downstream dependencies. Look at metrics like the typical error rate, response time, and the volume of requests sent to the downstream service. You can get these insights from your existing monitoring tools. If you don’t have monitoring in place, you can still implement a circuit breaker and use its built-in dashboard to gather this data.
Allow Breathing Room in the Circuit Breaker Configuration—Especially at First
If you're implementing Hystrix (or any circuit breaker) for the first time, it's a good idea to start with a more lenient configuration. Since you might not yet have monitoring in place, you won't know how often the downstream service fails or how it behaves under load. A strict configuration could unintentionally disrupt existing processes, so give your system some breathing room while you observe and learn.
Don't hardcode the configuration
It's best not to hardcode your circuit breaker settings. Instead, make them configurable via properties, a database, or an external configuration service. This way, if the settings need to be adjusted, you won’t have to redeploy your application—making it much easier to recover quickly and minimize business impact.
Account for App Instances in Your Configuration
When using per-instance circuit breaker settings, it’s important to think about how your application behaves at scale. Circuit breakers often use percentage-based thresholds, which makes them more adaptable than fixed-count mechanisms like rate limiters. Still, scaling can introduce unexpected issues.
For example, if you set a high request volume threshold, it might work fine in a single-instance setup. But once the app scales horizontally, each instance may receive fewer requests—potentially not enough to reach the threshold and trip the circuit breaker, even if the overall system is under stress. Always factor in your scaling strategy when defining these thresholds to avoid silent failures or delayed responses.
Takeaway
In this article, we explored how the Circuit Breaker pattern helps improve system resiliency.
However, it's just one piece of the puzzle. Other techniques—like retry mechanisms, the bulkhead pattern, and timeouts—also play a key role in building robust systems.
Make sure to subscribe to Code Curated so you don’t miss out when we cover these methods in future articles!


